This table contains a set of factors to apportion Census block group-level
data among the CMAP travel modeling subzones. Separate factors are provided
for apportioning housing unit, household, and population attributes. All
factors were determined by calculating the percentage of a block group's
housing units, households and population that were located in each of its
component blocks, according to the 2020 Decennial Census, and then assigning
each block to a subzone (based on the location of the block's centroid
point). Subzones that do not contain the centroid of any blocks with at least
one housing unit, household, person or job are not present in this table.
Use xwalk_blockgroup2subzone for data from the 2020 decennial census or
the American Community Survey (ACS) from 2020 onward. For data from the 2010
decennial census or ACS from 2010 through 2019, use
xwalk_blockgroup2subzone_2010.
xwalk_blockgroup2subzone
xwalk_blockgroup2subzone_2010Format
xwalk_blockgroup2subzone is a tibble with
22781 rows and
6 variables:
- geoid_blkgrp
Unique 12-digit block group ID, assigned by the Census Bureau. Corresponds to
blockgroup_sf(although that only includes the block groups in the 7-county CMAP region). Character.- subzone17
Numeric subzone ID. Corresponds to
subzone_sf. Integer.- hu_pct
Proportion of the block group's housing units (occupied or vacant) located in the specified subzone. Multiply this by a block group-level measure of a housing attribute (e.g. vacant homes) to estimate the subzone's portion. Double.
- hh_pct
Proportion of the block group's households (i.e. occupied housing units) living in the specified subzone. Multiply this by a block group-level measure of a household attribute (e.g. car-free households) to estimate the subzone's portion. Double.
- pop_pct
Proportion of the block group's total population (including group quarters) living in the specified subzone. Multiply this by a block group-level measure of a population attribute (e.g. race/ethnicity) to estimate the subzone's portion. Double.
- emp_pct
Proportion of the block group's total jobs located in the specified subzone. Multiply this by a block group-level measure of an employment attribute (e.g. retail jobs) to estimate the subzone's portion. Not available in
xwalk_blockgroup2subzone_2010. Double.
xwalk_blockgroup2subzone_2010 is a tibble with
21411 rows and
5 variables (no emp_pct).
Details
Other than in certain areas of Chicago, block groups tend to be significantly larger than subzones and have highly irregular boundaries, so in most cases the jobs, population, households and/or housing units in a block group are split across multiple subzones. For that reason, it is not appropriate to use a one-to-one block group-to-subzone assignment to apportion Census data among subzones, and this crosswalk should be used instead.
To use this crosswalk effectively, Census data should be joined to it (not
vice versa, since block group IDs appear multiple times in this table). Once
the data is joined, it should be multiplied by the appropriate factor
(depending whether the data of interest is measured at the housing unit,
household, person or job level), and then the result should be summed by
subzone ID. If calculating rates, this should only be done after the counts
have been summed to subzone. The resulting table can then be joined to
subzone_sf for mapping, if desired.
If your data is only available at the tract level, you can use
xwalk_tract2subzone for a tract-level allocation instead. If the subzone
geography is too granular for your needs, you can use zones instead with
xwalk_blockgroup2zone or xwalk_tract2zone.
Examples
# View the block group allocations for subzone17 == 1
dplyr::filter(xwalk_blockgroup2subzone, subzone17 == 1)
#> # A tibble: 4 × 6
#> geoid_blkgrp subzone17 hu_pct hh_pct pop_pct emp_pct
#> <chr> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 170310816001 1 0.285 0.290 0.324 0.0895
#> 2 170310816002 1 1 1 1 1
#> 3 170310817001 1 0.877 0.882 0.853 0.233
#> 4 170310817002 1 0.161 0.165 0.167 0.0517
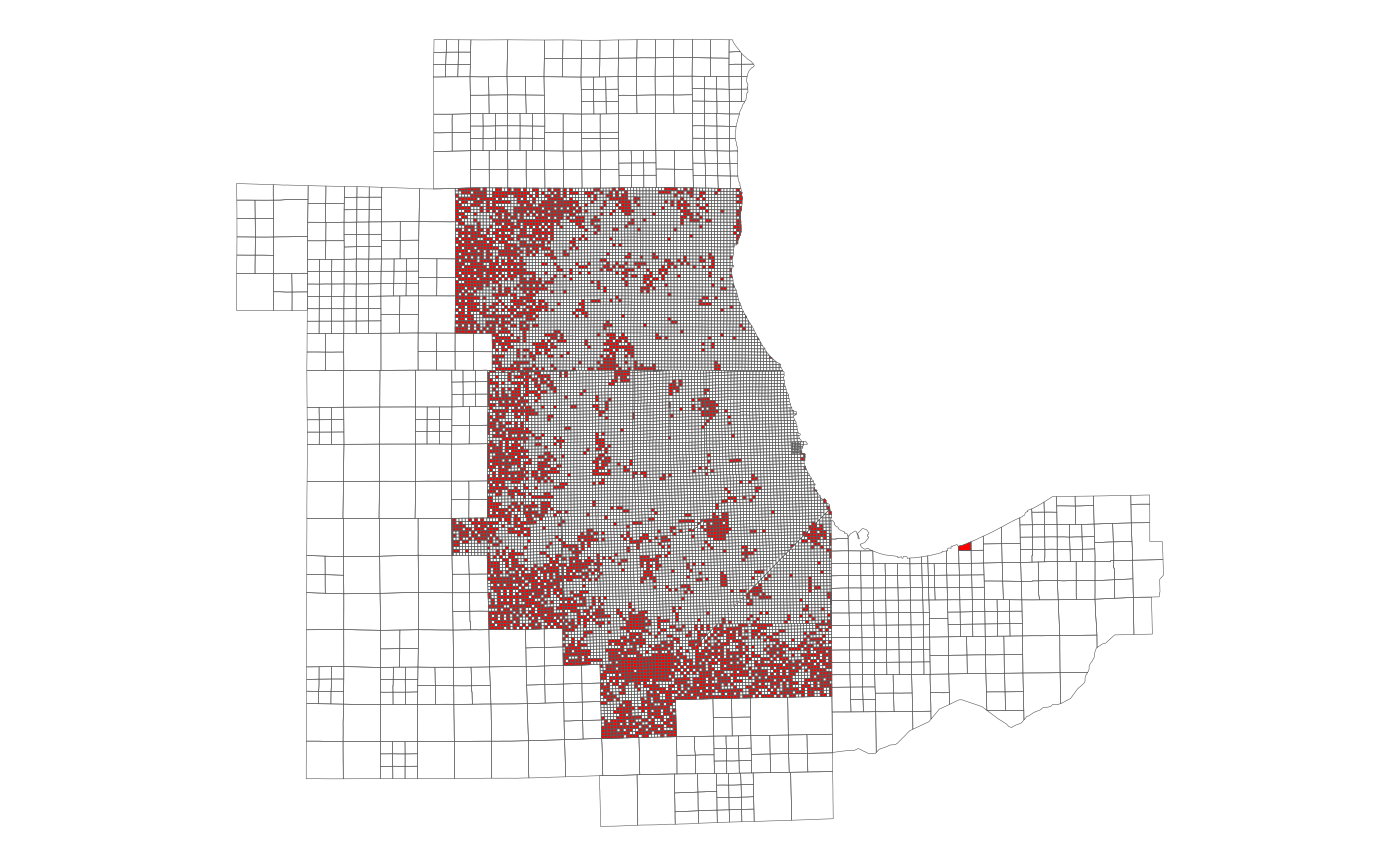
# Map the subzones missing from xwalk_blockgroup2subzone (i.e. no HU/HH/pop/emp)
library(ggplot2)
ggplot(dplyr::anti_join(subzone_sf, xwalk_blockgroup2subzone)) +
geom_sf(fill = "red", lwd = 0.1) +
geom_sf(data = subzone_sf, fill = NA, lwd = 0.1) +
theme_void()
#> Joining with `by = join_by(subzone17)`