Model calibration ensures that the various components of the overall model replicate observed data for a base year. Calibration requires adjusting parameters for individual sub-models to ensure that they each produce realistic results. Calibration is complete once model results match the observed patterns found in the Census, regional household travel surveys and transit origin-destination surveys. CMAP's ABM is calibrated to a base year of 2010 because the regional household travel survey data available were collected in 2007-08. Model validation is focused on comparing the final results of a calibrated model to other data sources such as daily traffic counts, daily transit boardings, and more recent Census data. A best practice within travel demand modeling is to use different datasets for model calibration and validation activities to double-check that the results replicate observed travel patterns. The CMAP ABM is run to reflect travel conditions for the year 2015. Validation demonstrates that the sub-models calibrated to 2010 conditions are able to represent the conditions in 2015. Data source information for each page can be found in the footer.
Introduction
Activity-based models (ABMs) are founded on the idea that people’s travel behavior is a result of their daily activities; i.e., the things people need to accomplish dictate where, when, and how they travel, and with whom. These models are more advanced than standard travel demand models because they seek to represent the choices made by individual travelers. In order to do this, the models must generate a schedule of daily activities for members of every household in the region, and then transform that information into sequences of trips that occur throughout the day. To accomplish this, ABMs use detailed information about the factors that affect travel decisions, including:
- Households – the number of adults, children, and workers; household income; the number of vehicles available
- People – age; work and school status; occupation
- Trips – purpose; destination; who is taking the trip; is it part of a sequence of trips that must be completed in a specific order
CMAP Modeling Area and Network
The modeling area extends beyond the 7-county CMAP region to include 21 counties. Only portions of Lee, Ogle, and LaSalle counties are included in the modeling area.
Model Steps
The following provides a brief outline of the major steps involved in running CMAP’s ABM. Preliminary sets of highway and transit trip assignments are run to generate realistic congested travel times that are used by CT-RAMP when daily activities are scheduled. The model also accounts for the relative ease or difficulty involved in reaching destinations using various modes of transportation, including driving, walking and using transit.
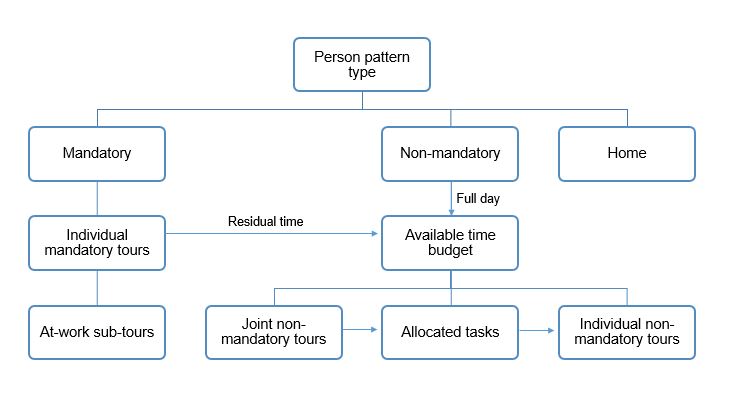
- Mandatory (work and school) – includes at least one out of home mandatory activity;
- Non-mandatory (other purposes) – includes at least one out of home non-mandatory activity but no out of home mandatory activities;
- Home – in home activities only, so no travel is involved.
These activities are modeled as joint choices so that decisions made by household members affect the decisions of other members of the household. The next sub-models estimate the frequency and time of day for mandatory activities. These are given a higher priority for scheduling than non-mandatory and home activities. Following the scheduling of mandatory activities, individuals have “residual time windows” which can be used to schedule other activities including joint travel with other household members.
The next sub-model estimates joint travel for household members. All characteristics of joint travel (travel purpose, individual household members traveling, destination and time of day) are simulated. Joint travel is conditional upon the available time window for each household member following the scheduling of mandatory activities.
The next sub-model generates maintenance tours, which cover shopping and other household errands. These tasks are allocated to a single household member to carry out, and the destinations and times of day are generated. These tours are developed sequentially for individuals to ensure consistency in their personal schedule.
The next sub-model simulates discretionary tours which are modeled for individual, not joint, travel. These are also modeled sequentially so that they could all realistically occur during an individual’s day.
The final sub-model simulates at-work tours – those tours that occur during the day with the workplace as the starting and ending location.
Population Synthesis
Using Census data and other socioeconomic information, a complete set of households for the CMAP modeling area is developed. This dataset contains all of the relevant attributes about each household and for each individual living in those households, which is required to run the ABM. While this population is statistically representative of the Census data, the actual households and individuals are “synthetic” in that they do not represent identifiable people and an individual household in the Census data may be replicated numerous times in order to generate a complete distribution of households in the modeling inputs.
The current population synthesis software used by CMAP is PopSynIII. The socioeconomic data developed from CMAP’s regional forecasting and Local Area Allocation procedures provide the subzone-level control values for all ON TO 2050 model scenarios. CMAP has greatly enhanced the functionality of PopSyn to enforce these controls and generate a distribution of enumerated households that account for the distribution of adults, workers and children within the agency’s forecasting procedures.
Individuals are classified into one of eight mutually exclusive categories:
- Full-time worker: Age 16+ working at least 35 hours per week for more than 30 weeks out of the year.
- Part-time worker: Age 16+ and a non-student employed less than full time.
- Non-working adult: Age 16-64, non-working and a non-student.
- Non-working senior: Age 65+, non-working and a non-student.
- Pre-school: Age under 6.
- Non-driving student: Age 6-15.
- Driving age student: Age 16-19, not a full-time worker or college student.
- University student: Age 18+ and school enrollment is college undergraduate or graduate school.
Population by Person Type
Note on "Full-time workers": The model defines full-time workers as persons working 30+ weeks in the year and 35+ hours per week. Full-time workers in the observed data are persons working 27+ weeks in the year and 35+ hours per week.

Households by Size
Household Characteristics
Households by
Income is in 1999 dollars.
Household Detail
Distribution of Adults Per Household by
Vehicle Ownership
Vehicle ownership plays an important role in individuals’ travel behavior decisions and helps define the set of travel mode options available to them. For example, households that own no vehicles may be dependent on transit to make their trips. Note that vehicle ownership refers to motor vehicles owned or leased by a household, including autos, pickup trucks, SUVs and motorcycles.
Number of Households by Vehicles Owned
Total Households: Model, Survey
Distribution of Vehicle Ownership by
Total Households: Model, SurveyIncome is in 1999 dollars.
Work Flows
Commute trips are an important part of a region’s overall travel pattern and are a key component of
congestion experienced on the transportation system, especially during the morning and evening hours.
Ensuring that commuters are traveling between the appropriate home and work locations is one important way
to verify that travel demand models reflect actual travel patterns.
Note there are two sources for observed data on this page. The first three tables use data from journey-to-work flows from the Census
Transportation Planning Package (CTPP). The remaining two charts use data from household travel surveys. CTPP data is generally used to
estimate models that address work flows due to the large sample of data included. Data from household travel surveys can be used to supplement
the journey-to-work information from the CTPP, as travel surveys offer more detailed information about the trips than the Census provides.
Modeled Journey to Work Flows
Observed Journey to Work Flows
Difference Model and Observed Journey to Work Flows
Origin and Destination Work Flows
FromTo
Modeled
Observed
Work Trips by Mode and Distance
of all work trips
Trips by Mode
The CT-RAMP model includes eleven options for travel modes. These include the non-motorized options of walking or cycling, as well as transit, taxis and school bus. There are six options for auto trips, which are categorized by the number of vehicle occupants and whether or not the trip includes a toll. Vehicle occupancy categories include single occupants, two people sharing a vehicle, or more than two people sharing a vehicle.
Trips by Person Type and Mode
of all trips
Trips by Household Income and Mode
of all trips
Tours
Tours are chains of trips that start at one location and return to that same location. A common example is a trip made from home to work, followed by another commute trip returning home later in the day. Tours are composed of a minimum of two trips. Tours may also contain sub-tours, for example traveling from work to an external meeting and then returning to work. Tours may be completed by an individual or can include multiple people traveling together.
Daily activities are categorized into three types: mandatory, nonmandatory, or home. Activities are placed within these three categories based on the relative importance of the role they play in defining one’s day. Mandatory activities (which include work and school) are the most inflexible in terms of when they occur and where they are located. Nonmandatory activities have greater flexibility in when they occur and where their locations are. Home tours are stationary and are not assigned a travel mode.
Daily Activity Patterns By Person Type
of all tours
Tours by Person Type
Tour Arrival and Departure Time of Day
Trip Activities
The CMAP ABM classifies trips into ten activity types. Activities can be grouped into two categories according to their priority in determining an individual’s schedule: mandatory and nonmandatory. Mandatory activities include:
- Work - Working at regular workplace.
- University - Attending college.
- School - Attending school grades K-12.
The remaining activities are all considered nonmandatory:
- Shopping - Shopping away from home.
- Escort - Picking up/dropping off passengers (auto trips only).
- Eating out - Eating outside of home.
- Work-based - A subset of activities (such as going to lunch or traveling to meet a client) that occur with the place of work as the anchor location.
- Maintenance - Activities that include medical appointments and other personal business or services that people engage in, excluding shopping and escorting activities.
- Discretionary - Engaging in social or recreational activities; attending sporting or cultural events; and attending religious activities or performing volunteer activities.
Trip Activities
Trips by Person Type and Purpose
of all trips
Trips by Purpose and Distance
of all trips
Transit Trips
Transit is a vital part of the transportation system in northeastern Illinois and more than 600 million transit trips are made annually. It is important to properly calibrate such a key travel mode to ensure that the modeled transit trips reflect the travel sheds actually served by transit.
Modeled vs. Observed Transit Trips Origin and Destination
The scatterplot includes a point for each origin/destination pair. A map of origin/destination areas is shown below, with the CMAP region shaded for reference.
r2 =
Transit Trips by
Total transit trips: 1.63M Model, Survey
Transit Access
The Drive to Transit access mode includes individuals parking at transit stations (Park and Ride) and those who are dropped off at the station (Kiss and Ride). The Walk to Transit access mode includes people walking or cycling to get to transit.
Modeled Transit Access
CMAP ABM - 2010 Scenario
Observed Transit Access
Travel Tracker Survey, 2007-2008
Synthetic Household Validation
This map displays the difference between modeled and observed data for selected household attributes summarized by U.S. Census Public Use Microdata Areas (PUMAs). PUMAs are geographic areas defined by the U.S. Census Bureau that contain a minimum of 100,000 people.
Attribute: 0-vehicle households
Choose from household size, household income, number of workers, and number of vehicles in households by clicking the category button and selecting the specific household type from the dropdown. Hover over each PUMA to display the values for modeled and observed data.
Example: In the model, 22.7% of households in northeast Lake County are 1-person households. According to PUMS, 27.2% of households in northeast Lake County are 1-person households. This is a difference of -4.5 percentage points.
Highway Assignment
During Highway Assignment, the individual motor vehicle trips developed by the ABM are routed along the model transportation network from origin to destination in order to estimate traffic flows and network conditions. As additional vehicles attempt to use the same roadway segments during the assignment, travel becomes more congested and travel times increase. The assignment procedures implement a series of steps moving various portions of traffic onto alternative routes in an attempt to reduce congestion and minimize travel costs. Equilibrium is reached within the highway assignment when vehicles cannot change paths without negatively impacting travel times. Once equilibrium is reached, the volume of vehicles on each roadway segment is retained and can be used to calculate standard measures such as vehicle miles of travel (VMT).
Daily VMT Shares by County
Daily VMT Shares by County and Facility Type
Modeled vs. Observed Average Daily Link Volumes
r2 =
Daily VMT By Interstate
This comparison examines vehicles separated into two categories: auto (which includes cars, SUVs, pickup trucks, etc. that people drive for their personal use) and commercial vehicles (which include package delivery trucks all of the way up to tractor-trailers) used to conduct business activities.
Truck volumes on I-190 not shown due to bar scale. Model and observed values equals 11,512 and 9,917 respectively.
Auto
Truck
Daily VMT by Volume Range
Root Mean Squared Error Analysis
Links were grouped into volume bins based on the observed traffic counts (AADT) and linear regression analyses were completed for each group. The root mean squared error (RMSE) is a measure commonly-used for model validation analyses and compares the average difference between the observed values and the modeled volume predicted by the linear regression. The percent RMSE standardizes the value by dividing it by the average of the AADT.
Target values represent the standard maximum acceptable root mean squared error from the Florida Department of Transportation, which are often cited as model validation goals.
Transit Assignment
The analysis of transit assignment results generally focus on comparing the number of transit boardings estimated by the model to observed boardings. The CMAP model transit network includes the following modes:
- Heavy Rail – operated by the Chicago Transit Authority (CTA) in Chicago and some surrounding communities.
- Commuter Rail – operated by Metra throughout the CMAP region.
- Bus – operated by CTA (in Chicago and some surrounding communities) and by Pace Suburban Bus (in northeastern Illinois, mostly outside of Chicago).
Transit Boardings by Mode
Transit boardings include average weekday boardings for fixed-route service. Demand responsive dial-a-ride, call and ride, or ADA paratransit services are not included.
Transit Boardings by Line
CTA
Metra
Commute Trips Validation
The analysis of commute trips focuses on comparing the patterns of travel from home (place of residence) to work (primary place of work).
Modeled vs. Observed Journey to Work Flows
The scatterplot includes a point for each home/work county pair in the modeling area. Only a portion of Lee, Ogle, and LaSalle counties are included in the model data (refer to map in Introduction). A modeling area county map is shown below, with the standard CMAP region shaded for reference.
r2
=
Modeled Journey to Work Flows
Observed Journey to Work Flows
Difference Model and Observed Journey to Work Flows